Centauri: Enabling Efficient Scheduling for Communication-Computation Overlap in Large Model Training via Communication Partitioning
简介
这篇文章主要想解决通信和计算重叠的优化问题,感觉作者想要“大一统”地去优化各种并行算法下的计算和通信重叠,但是文章主要只针对了LLM的场景描述,实验部分说了几种并行算法的混合(FSDP + DP / TP + PP + DP),没有细节讨论这些并行算法咋混合的(哪些模型分区用哪种并行,姑且认为是和其他自动并行正交)。实现基于 Megatron-LM 目前没找到代码在哪里。为了解决这个问题作者提了好几种抽象的概念(定义了好几种术语,看的头晕。。实际感觉挺 straightforward,后文用我的自己的理解来描述了,不知道和作者原思路是否一致。)。文章也没有描述怎么得到计算和通信代价的,直觉上如果输入变化了,重叠方式也应该对应变化(不知道overlap 的方式是静态还是动态)。
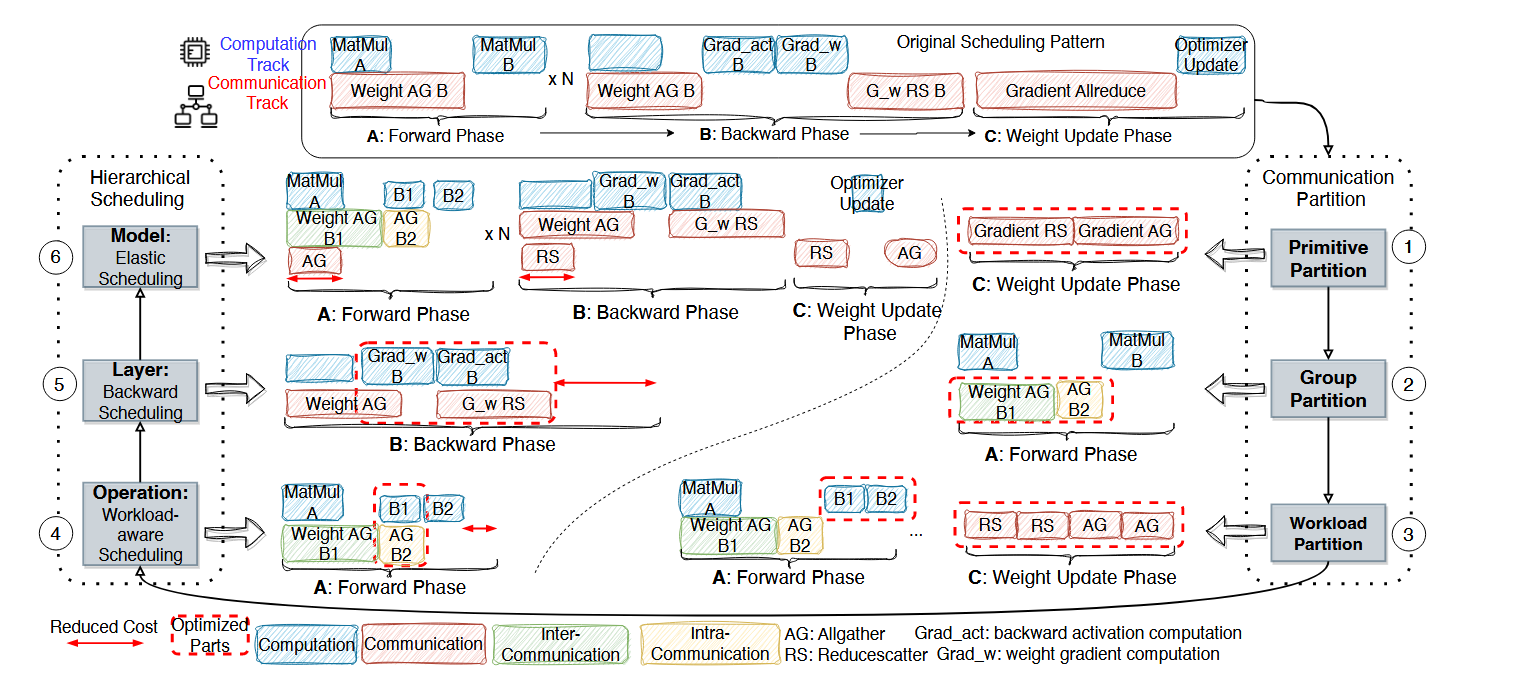
分两个大步骤来解决计算和通信重叠问题(每个大步骤里面分3个小步骤,看上图):1. communication partition:怎么分解这个 communication 操作(把通信操作 / 算子计算操作分解为更加细粒度)2. hierarchical scheduling:怎么调度,具体就是怎么排 computation 和 communication 让他们依赖是正确的,并且能最大程度重叠。
communication partition
主要分3个维度(不知道为啥这样取名 ;-| ):primitive, group, workload
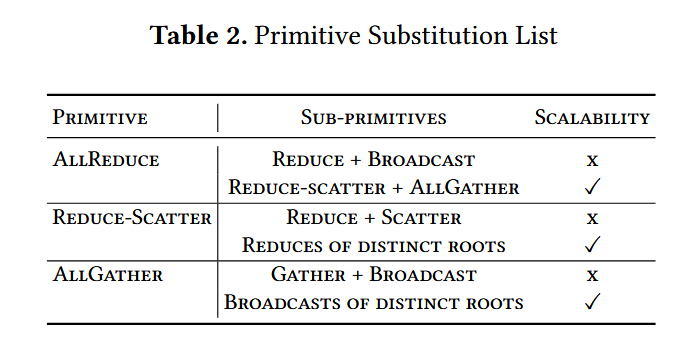
primitive partition: 做通信原语替换,作者列举了一些替换的例子。在这里的目的估计是想把大的通信原语粒度拆小。也提了拆小并不一定好。
group partition:这个操作我理解也是常见的操作了,把 inter-node 和 intra-node 区分开(异构场景节点间的通信带宽不一样)。不知道图里面是不是这个意思,把 all-gather B 分解成了两个 all-gather B1 和 all-gather B2(带宽大的组到一个 group 做 gather 通信)。
workload partition:这个直觉上就是把计算和通信再拆小,看大图,matmul B 这个操作就能和通信并行,传一部分的时候我就算一部分,另一部分传过来我继续接着算。
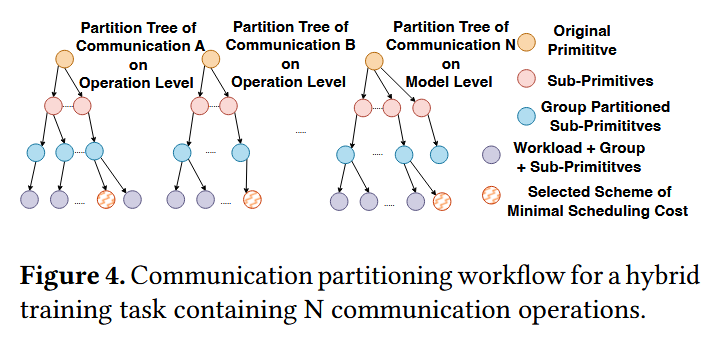
整个 communication partition 的 workflow 就如下图所示(从上到下构建一个这样的树结构,选一个最小 cost ,cost 估算不知道咋弄得):
hierarchical scheduling
这一部分把调度又分三个层次:operation level(起初一看名字�以为是算子级,结果指的是前向阶段), layer level(反向阶段),model level(混合下前面的阶段)
operation level: 优化前向传播,直接贪婪一手,没依赖的可以重叠直接放一起执行,有依赖的按顺序排下去就行。作者提到了拆分粒度过细不行(通信开销变大etc...),所以需要一个合适的拆分方式,提了一个算法(从层次来划分,这个不知道为啥不放在 partition 里面,而是放在了 scheduling,这个算法很直白就不贴了,没证明)。
layer level:优化方向传播,这里作者说在计算反向传播时候然就能存在一种最优调度(看下图,算权重梯度时G_w和激活梯度的通信重叠W_AG)。这里恐怕还需要讨论下 W_AG 和 G_W 的 cost 如何得到的吧。

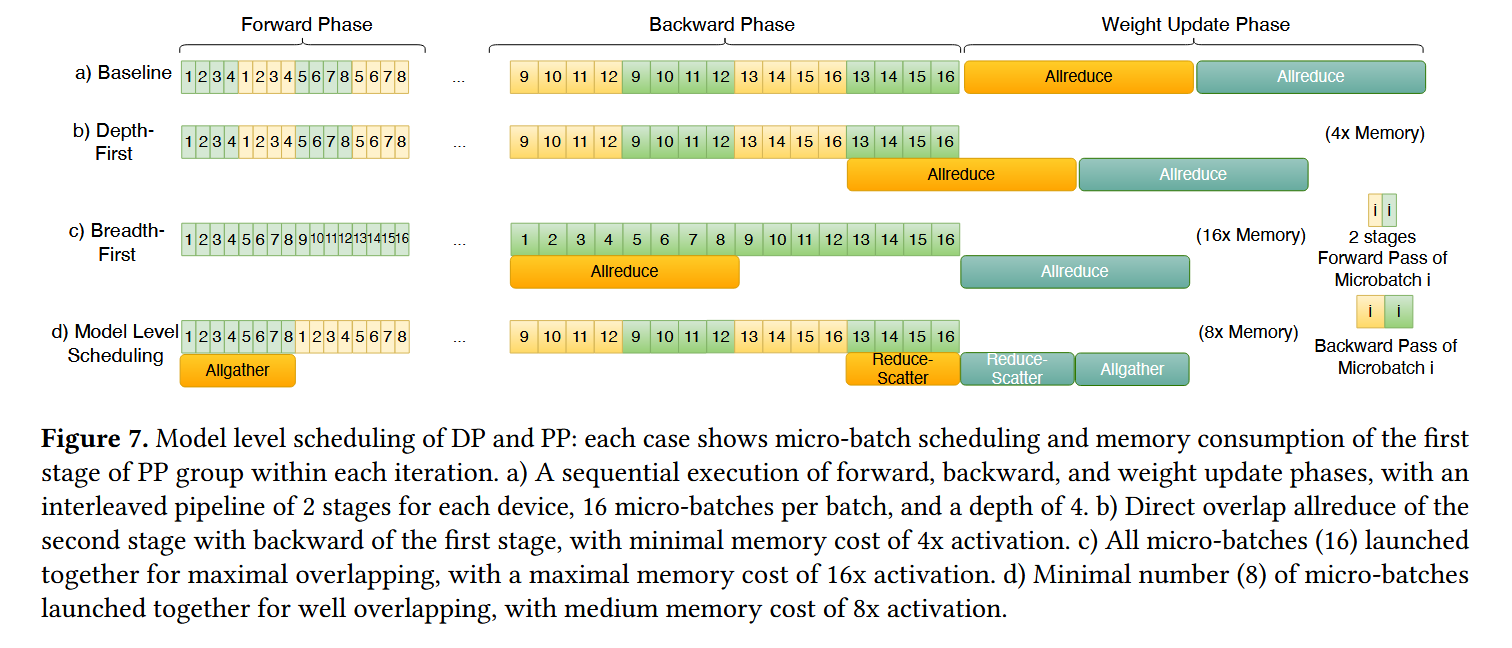
model level: 如何重叠前向和反向传播。看下图,分了多个 microbatch 多 stage 的话,那就可以用不同方式来把权重更新操作延后并行了。总共有2 * 16条数据。baseline 的话每个交叠串行执行,最后同步梯度,b) 黄色代表的microbatch完成了反向传播,可以开始收集梯度了,然后等绿色最后梯度累积。c) 两个 microbatch 分开搞,黄色的完了就能收集了 d) 黄色的搞完反向了先 reduce-scatter 一下,轮到黄色前向传播的时候在gather下更新为最新权重。
其实这个思路感觉用到 N 层 decoder 模型也是一样的,算第 N 层模型的前向传播时,我收集 N+1 的梯度。